
Elastic search is soon going to be the next big thing in the tech ecosystem. Because you have landed here, you might already be a little familiar with the technology. Or you might be at an intermediate level and want to understand it in depth. But no matter which level you are at, you will be a pro by the end of this blog. I will take you through all the ins and outs of Elasticsearch. We will also take a deep dive into Elasticsearch use cases while also understanding how exactly it works.
Elasticsearch: The Definition

Source: elastic-product-logos-package.zip
You must have heard (or read on Google) the definition of Elasticsearch:
"It is a search engine that lays its foundation on Lucene library to provide the users with a distributed, multitenant-capable full-text search engine capabilities with an HTTP web interface and schema-free JSON documents.”
Let us break it down for you:
- Elasticsearch is nothing major but an analytics search engine that is distributed and open-source.
- Elasticsearch has been developed in Java, and it is built on Apache Lucene.
- Initially, it was introduced as a scalable version of the Lucene open-source search framework.
- As of now, it can also scale Lucene indices horizontally.
Using Elasticsearch, you can search, analyze, and store large volumes of data in near real-time without any hassle. It generates answers in milliseconds.
But Google does that too. What makes Elastic search so special then? Using this search engine, you can achieve fast search responses, since it searches the text as an index instead of searching it directly.
Moreover, it also uses a structure based on documents instead of tables and schemas. This way, it brings out the true potential of extensive REST APIs for storing and searching the data. In short, Elasticsearch is a server designed to process JSON requests and produce JSON data as results.
Elasticsearch and its surrounding ecosystem of components (Elastic Stack) have been used for a number of use cases. Right from a simple search on a website or a document to collecting and analyzing log data to a business intelligence tool for data analysis and visualization - it’s an all-in-one package.
But how exactly did this simple search engine become so popular? And how does it now rank amongst the 10 most popular database management systems?
The credit goes to Elasticsearch use cases that can get you a really high return on investment. But before getting into it, let’s first understand how elastic search works.
Build Your Dream Project With The Best in Class Team
We specialise in developing software solutions that maximize ROI without compromising on the quality.
Hire UsHow does Elasticsearch work?
Here’s a quick look at some basic concepts of elastic search data organization and backend components.
Basic Logical Concepts in Elasticsearch
To understand Elasticsearch functionalities better, you first need to be familiar with these basic concepts:
Documents in Elasticsearch
A document is the basic unit of information. You can index documents in the global internet data interchange format, i.e Elasticsearch expressed in JSON. Think of a document like a row in a relational database, representing a given entity you are searching for. In Elasticsearch, a document doesn’t necessarily have to be just text; it can be any structured data encoded in JSON.
Similarly, that data can be numbers, strings, and dates. Each document has a unique ID and a given data type that describes the type of document. For instance, it could be an encyclopedia article or log entries from a web server.
Indices in Elasticsearch
These are the collection of documents having similar characteristics. Indices are the highest level entities that you can query against in Elasticsearch. Consider these as a database in a relational database schema where all documents are logically related.
Every index comes with a name that you can use to identify it while indexing, searching, updating, or deleting an operation against the documents present in it. For instance, in e-Commerce, you can have dedicated indices for each: your customers, products, orders, and so on.
Inverted Index
In Elasticsearch, an index itself is referred to as an inverted index. It represents the mechanism behind the functionality of all search engines. This data structure stores a mapping from content. It could be words or numbers, locations in a document, or a set of documents. In a nutshell, you can call an inverted index a hashmap-like data structure that helps you go from a word to a document. An inverted index is responsible for storing strings directly. It follows a schematic approach to the same.
First, it splits each document into individual search terms. Then, it maps them back to the documents in which the search terms appear. Distributed inverted indices make Elasticsearch more powerful since they enable it to find the best matches for full-text searches.
Back-end components in Elasticsearch
In addition to logical concepts, here’s what you should know about the backend components in Elasticsearch.
Clusters in Elasticsearch backend
In Elasticsearch, a cluster represents a group of interconnected node instances. An Elasticsearch cluster can help you with searching, indexing, and distributing tasks across all the nodes present in the entire cluster.
Nodes in Elasticsearch backend
A node in Elasticsearch is a single server that is a part of a cluster. It stores data and participates in various processes. Examples of these processes include search capabilities and cluster indexing.
You can configure an Elasticsearch node in different ways:
Master Node: It controls the Elasticsearch cluster. It also handles all cluster-wide operations like adding or removing nodes and creating or deleting an index.
Data Node: This node stores data and helps you execute data-related operations, such as searching and aggregation.
Client Node: It is responsible for forwarding data-related requests to data nodes and cluster requests to the master node.
Shards in Elasticsearch
Elasticsearch allows you to subdivide the index into multiple pieces known as shards. You can host shards on any node within a cluster since each shard is a fully functional and independent index.
Elasticsearch offers data redundancy to protect against hardware failures while increasing query capacity as you add nodes to a cluster. Shards achieve the same in two steps. First, they distribute the documents in an index across multiple shards, and then they distribute them across multiple nodes.
Replicas in Elasticsearch
Using Elasticsearch, you can easily make one or more copies of your index’s shards called replica shards or just replicas. A replica shard is nothing but a copy of a primary shard.
Replicas help you protect against hardware failure by providing you with redundant copies of your data. They also help you increase your capacity to serve read requests, e.g., searching or retrieving a document.
The Elastic Stack (ELK)
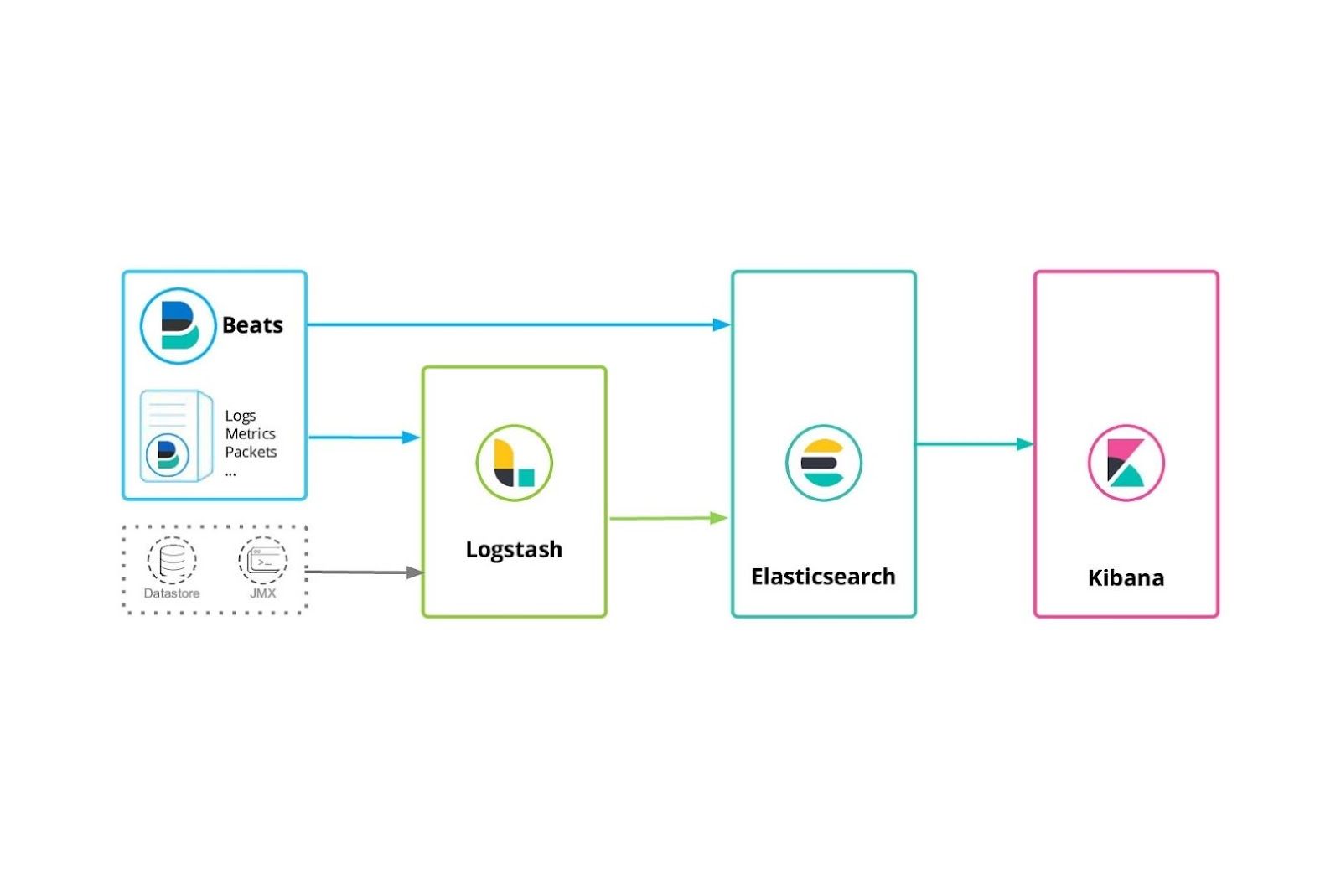
We will be using this term a lot to discuss Elasticsearch use cases. Hence, it is a good idea to know a bit about it. Elastic Stack consists of a set of open-source tools for deploying data analysis, data ingestion, enrichment, storage, and visualization. It is commonly known as the ELK Stack, where each letter represents its three components: Elasticsearch, Logstash, and Kibana. Now, it also includes Beats.
Kibana for data visualization
Kibana is a tool for data visualization and management in Elasticsearch. It provides you with real-time pie charts, line graphs, histograms, and maps. You can also use Kibana to visualize your Elasticsearch data and navigate the ELK Stack. Moreover, Kibana lets you select how you want to shape your data.
Logstash for data processing
We use Logstash to aggregate and process data and then send it to Elasticsearch. Logstash is an open-source data processing pipeline that works on the server-side. It ingests data from various sources simultaneously and helps you form the right data collection.
Beats for data shipping
Beats (the newest addition to the ELK Stack) is a collection of lightweight, single-purpose data shipping agents. You can use Beats to send data from multiple (hundreds/thousands) machines and systems to Logstash. Beats are an ideal choice for gathering data because of their versatile nature. They can work with your servers and containers, or you can deploy them as functions.
In these ways and more, it can help you centralize data in Elasticsearch. For example, Filebeat can sit on your server, monitor log files it receives, parse them, and import them into Elasticsearch.
Want To Build An App For Your Startup?
We will help you clarify your requirements, select the right tools and reduce your app development costs.
Book a free consultation call with usElasticsearch Use Cases
Now that we have understood what Elasticsearch is, it is time to take a look at Elasticsearch use cases. We will discuss the logical concepts behind it and its architecture to figure out why and how it can be used for a variety of use cases.
Let’s start with Elasticsearch primary use cases and how companies are using them today.
Elasticsearch for application Search
You can use Elasticsearch for applications relying heavily on a search platform for operations like accessing, retrieving, reporting the data.
Elasticsearch for website Search
This search helps websites that store a lot of content with effective and accurate searches. Elasticsearch is steadily gaining momentum in this domain.
Elasticsearch for Enterprise Search
Elasticsearch facilitates enterprise-wide search, including document search, blog search, people search, e-Commerce product search, and any other form of search you can think of.
Enterprise search is already being used in the search solutions of some very popular websites and web apps. Talking from an enterprise-specific perspective, Elasticsearch is getting used in company intranets to reach desired goals.
Elasticsearch for logging and log analytics
By now, you must have understood that we use Elasticsearch mostly to ingest and analyze log data in near-real-time. It does all of that in a scalable manner. In addition to that, it also provides you with crucial operational insights on log metrics to drive actions.
Elasticsearch for infrastructure metrics and container monitoring
Many companies use the Elastic Stack (ELK Stack) for analyzing various metrics, which requires gathering data across several performance parameters that vary by use case.
Elasticsearch for security analytics
Security analysis is yet another vital use case of Elasticsearch. You can analyze access logs and similar logs in the system security with the help of the ELK Stack. It eventually offers a more complete picture of what is happening across your systems in real-time.
Elasticsearch for business analytics
ELK Stack has several features that make it a good option as a business analytics tool. But it comes with a steep learning curve, especially for organizations having multiple data sources other than Elasticsearch.

How Big Companies Are Using Elasticsearch

Although the concept is still relatively new, many corporate giants have already begun to leverage Elasticsearch use cases.
Elasticsearch in Netflix
Netflix depends on the ELK Stack greatly for various operations. For example, they use it for monitoring and analyzing customer service processes and security logs. In fact, the underlying engine behind Netflix’s messaging system is Elasticsearch itself.
Moreover, Netflix decided to go with Elasticsearch for the fascinating features it offers: its extension model, flexible schema, automatic sharding and replication, and its ecosystem with many plugins.
Initially, the company had only a few isolated deployments of Elasticsearch. However, It has steadily increased its use of Elasticsearch to over a dozen clusters consisting of several hundred nodes.
Elasticsearch in eBay
eBay uses Elasticsearch for its countless business-critical text search and analytics to create a custom Elasticsearch-as-a-Service platform. This platform allows easy Elasticsearch cluster provisioning on the company’s internal OpenStack-based cloud platform.
Elasticsearch in Walmart
Walmart harnesses the power and features of Elastic Stack to reveal the hidden potential of its data. ELK Stack is helping Walmart to gain insights related to its customer purchasing patterns while tracking store performance metrics and holiday analytics.
Walmart also makes use of ELK’s security features for alerting for anomaly detection, establishing strong security with SSO, and monitoring for DevOps.
We Used Elasticsearch To Build Digital Collections For NINS

We, at Third Rock Techkno, believe in utilizing the best to create the best.
National Institute For Newman Studies, an organization dedicated to imparting education on John Henry Newman’s work, wanted to digitize their resources spanning over 25000 images and documents. They approached us to build a digital, highly organized, and accessible database for the same. We knew this level of search facilities required an advanced search engine like Elasticsearch.
So we used it to build the solution in the form of a portal where curators can scan and upload these resources hassle-free. Thousands of users now have instant access to decades-old documents in an instant.
See All Case-studies : <!--td {border: 1px solid #cccccc;}br {mso-data-placement:same-cell;}-->
The Bottom Line
Elasticsearch is more than just a search engine. Elasticsearch use cases include search, analytics, and data processing and storage. Also, it is fast and scalable. All thanks to its underlying architecture and components.
If you have a product idea that could benefit from Elasticsearch, let’s talk. Our experts can guide you on how to use it for maximum software efficiency. Book a free consultation here.
Looking For Expert Guidance on Your Dream Project?
Our diverse team of industry leading veterans can help you build the most viable solution.
Schedule a free consultation callKrunal Shah
Krunal Shah is the CTO and Co-founder at Third Rock Techkno. With extensive experience gained over a decade, Krunal helps his clients build software solutions that stand out in the industry and are lighter on the pocket.

